This document is the result of research on the topic of CPU/Memory Limits and Requests for Kubernetes, to provide engineers with a better understanding of how such configuration work and can affect the execution and performance of services.
Requests and Limits are the mechanisms k8s uses to control the utilisation of resources such as CPU and memory.
Requests are what the container is guaranteed to get. If a container requests a resource, the kube-scheduler will only schedule it on a node that can give it that resource.
Limits, on the other hand, enforce rules. They make sure a container never goes above a value. The kubelet only allows the container to go up to the limit and then it’s restricted.
Let’s take a look at an example limits and requests configuration.
containers:
- name: container1
image: busybox
resources: null
requests:
cpu: 200m
memory: 32Mi
limits:
cpu: 250m
memory: 64Mi
The Kubernetes scheduler uses the values of CPU and memory to figure out where to run the pods.
Each container in the pod can set its requests and limits, and these are all additive.
In an ideal world, pods should be continuously using exactly the amount of resources requested. But in the real world resource usage is never regular or predictable, that’s why we can consider a 25% margin up and down the request value as a good situation.If the usage is much lower than the request, we are wasting money. If it is higher, we are risking performance issues in the node.
It is important to note that the value represents the relative share of CPU time a container will receive when there is contention for CPU resources. It does not represent the actual CPU time each container will receive.
CPU
CPU resources are defined in millicores, if a container needs two full cores to run the value needed will be 2000m.
One thing to be aware of is that if the value is larger than the core count of the biggest cluster node, the pod will never be scheduled. This also applies to memory.
So unless the app is specifically designed to take advantage of multiple cores, it’s usually a best practice to keep the CPU request at one or below and then run more replicas to scale it out.
CPU is considered a compressible resource, if the app starts hitting the CPU limits, Kubernetes will start to throttle the container: this means the CPU will be artificially restricted giving the app potentially worse performance. However, it won’t be terminated or evicted.
Memory
Memory resources are defined in bytes. Typically it’s given a value in mebibyte, but it can be configured with anything from bytes to petabytes.
Unlike the CPU, memory is not compressible. Because there’s no way to throttle memory usage, if a container goes above the memory limit, it will be terminated.
CPU Limits and Quotas
CPU Limit is implemented using CFS bandwidth controller (a subsystem/extension of CFS scheduler), which uses values specified in cpu.cfs_period_us and cpu.cfs_quota_us (us = μ, microseconds) to control how much time is available to each control group.
cpu.cfs_period_us: length of the accounting period, also in microseconds. This is configured to 100,000 in Kubernetes.
cpu.cfs_quota_us: the amount of CPU time (in microseconds) available to the group during each accounting period. This value is taken from the limits.cpu.
1 vCPU == 1000m == 100,000us
0.5vCPU == 500m == 50,000us
Quota calculation
Considering the definitions above, the quota of CPU time dedicated to a process is calculated as follows:
quota_us = limits.cpu / requests.cpu * 100000us
Let’s try that on an example configuration:
web_app:
resources:
requests.cpu: 1000m
quota_us = 1000m / 1000m * 100000us = 100000us = 100ms
Assuming the service takes 200ms to respond and there is no contention, it will be guaranteed the 200ms of uninterrupted CPU time, which equals two consecutive quota slots.
Let’s consider a different configuration for the same service but with limits involved:
web_app:
resources:
requests.cpu: 1000m
limits.cpu: 500m
quota_us = 500m / 1000m * 100000us = 50000us = 50ms
The service only has a quota of 50ms every period (100.000µs): this means that to fulfil a single request that takes 200ms it will have to use 4 quota slots, interleaved with throttled slots.
The same request now takes 350ms to respond!
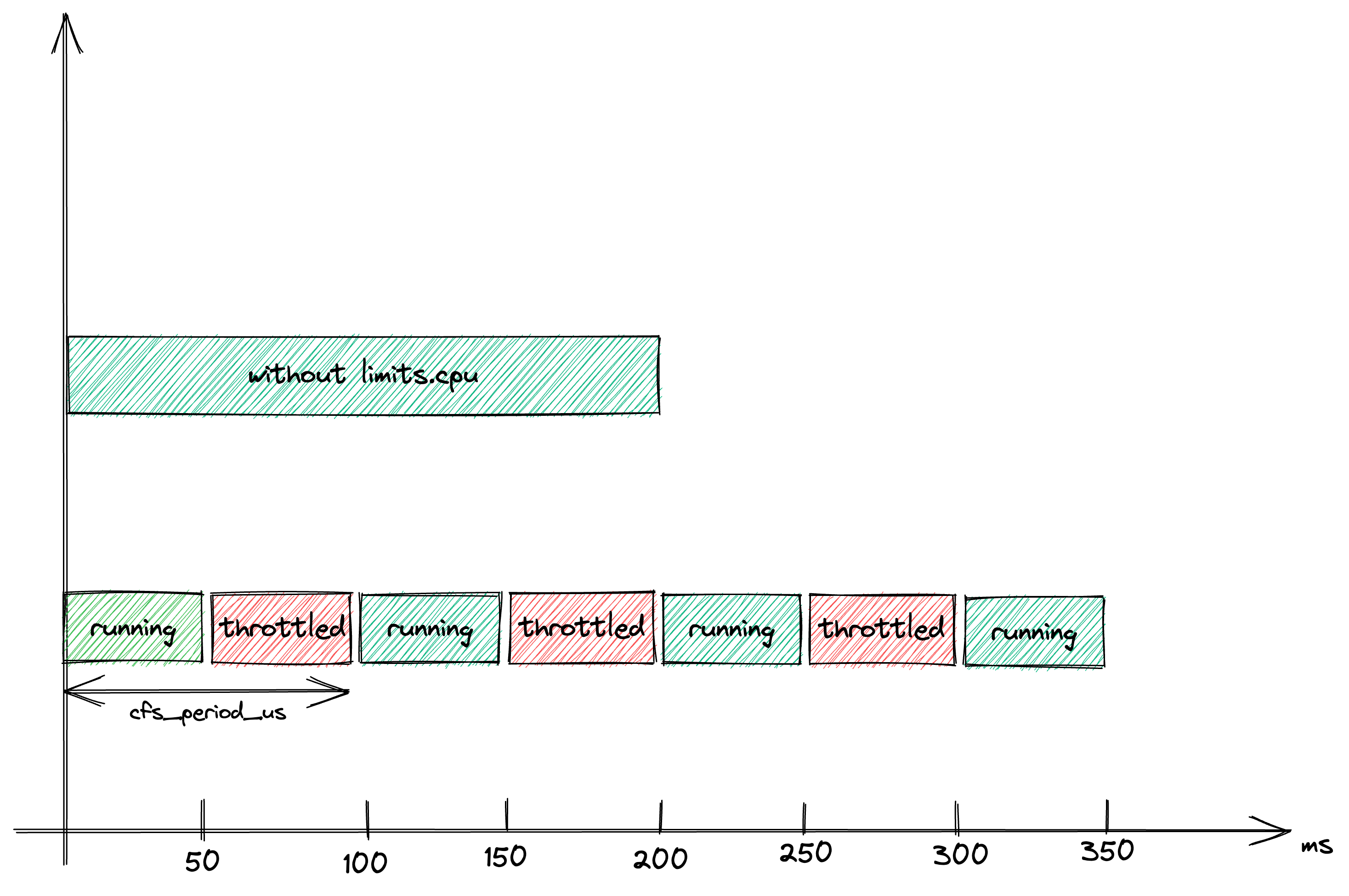
To avoid such situations, Kubernetes will throw an error and will not run the container when limits.cpu < requests.cpu
This might seem an obvious result of the above condition but the opposite doesn’t necessarily mean that the service will never throttle.
Throttling on low CPU usage
Imagine a pod with a CPU limit of 100m, which is equivalent to 1/10 vCPU.
The pod does nothing for 10 minutes, then uses the CPU nonstop for 200ms. The usage during the burst is equivalent to 2/10 vCPU, hence the pod is over its limit and will be throttled.
On the other hand, the average CPU usage will be incredibly low. The burst is so tiny (200 milliseconds) that it won’t show up in any graphs.
Removing CPU Limits
As many articles state, there have been positive experiences in the Kubernetes community of running containers without CPU Limits (Reference section: no. 7 and 8).
But, even though it may seem like an easy trick that achieves lower latencies and better CPU usage, it’s not always the case nor it’s that easy, for example:
- in Kubernetes: Make your services faster by removing CPU limits, the author explains they had to isolate unbounded services to dedicated nodes, to mitigate them from using too many resources in a node shared with bounded services;
- in Did Kubernetes Make My p95s Worse? - Jian Cheung & Stephen Chan, Airbnb, the speakers show how in the early days of AirBnB they decided to not set CPU Limits because they thought it would hurt performance, but that turned out to be worse than expected, creating a noisy neighbours effect, where a small number of services ends up dominating the CPU time;
- in For the love of God, stop using CPU limits on Kubernetes, the author suggests setting a requests quota and removing any CPU limit, and even if this can work for a majority of scenarios, it’s not a golden rule because as described above can lead to one or more services starve the rest.
Namespace resource allocation
People can forget to set the requests value or someone might intentionally set their limits very high in order to obtain more than a fair amount of resources.
To prevent these scenarios, Resource Quotas and Limit Ranges can be assigned.
For example, a very strict resource quota can be set on the development namespace while no quota is specified on the production one.
A Limit Range, instead, enforces itself on individual containers. This can help prevent the creation of tiny or massive containers inside the namespace. It’s important to note that if the default section is not set and the minimum or maximum section is set, then the minimum or the maximum will become the default for each container.
Key takeaways
- Throttling in very low numbers is physiological to services running in a distributed system with shared resources
- Monitor resource usage and requests/limits thresholds to fine-tune each service configuration
- Removing CPU Limits can bring benefits but consider the nature of each service running in the cluster before changing that configuration
- CPU bound vs IO bound applications, bursting vs constant request rates
- Benchmarking each service under load gives a good idea of the resource usage and how to configure it
Appendix
1. How pod specs are propagated
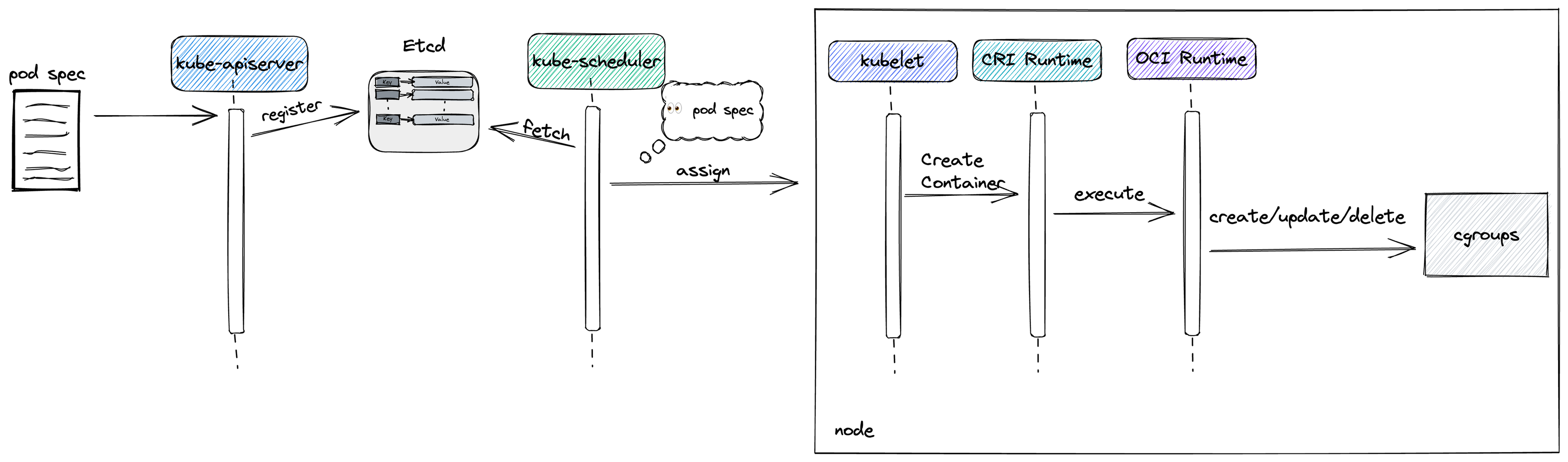
- Pod spec is registered in etcd through the kube-apiserver
- kube-scheduler fetches newly registered pods from etcd and assigns a node to each pod referring to resource requests
- kubelet fetches assigned pod spec in every sync period and calculates the differences between running containers and pod spec
- kubelet calls CreateContainer operation on the CRI Runtime, after converting CPU cores into periods
- CRI Runtime executes OCI Runtime binary to create a container with OCI Spec JSON
- OCI Runtime creates/updates/deletes cgroups accordingly
2. QoS Classes
When Kubernetes creates a Pod, it assigns one of the following QoS classes depending on the condition
| QoS Class | Condition | Priority (lower is better) |
|---|---|---|
| Guaranteed | Limits and optionally requests (not equal to 0) are set for all resources across all containers and they are equal | 1 |
| Burstable | Requests and optionally limits are set (not equal to 0) for one or more resources across one or more containers, and they are not equal | 2 |
| Best Effort | Requests and limits are not set for all of the resources, across all containers | 3 |
References
- Resource Management for Pods and Containers
- Assign CPU Resources to Containers and Pods
- Assign Memory Resources to Containers and Pods
- Container Runtime Interface (CRI)
- Configure Quality of Service for Pods
- CFS Scheduler on kernel.org
- For the love of God, stop using CPU limits on Kubernetes
- Kubernetes: Make your services faster by removing CPU limits
- Kubernetes failure stories
- HN conversation about removing CPU Limits
- CPU Throttling - Unthrottled: Fixing CPU limits in the Cloud
- Throttling: New Developments in Application Performance with CPU Limits - Dave Chiluk, Indeed
- Resource Requests and Limits Under the Hood: The Journey of a Pod Spec - Kohei Ota & Kaslin Fields
- 10 More Weird Ways to Blow Up Your Kubernetes - Jian Cheung & Joseph Kim, Airbnb
- Did Kubernetes Make My p95s Worse? - Jian Cheung & Stephen Chan, Airbnb